Task01决策树
先解决几个概念问题,比如信息量,信息熵等,这里借鉴【忆臻】大佬在知乎上的解释。
信息量
信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如湖南产生的地震了;越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了(肯定发生嘛,没什么信息量)。这很好理解!
- 一个具体事件的信息量应该是随着其发生概率而递减的,且不能为负。
- 如果我们有俩个不相关的事件x和y,那么我们观察到的俩个事件同时发生时获得的信息应该等于观察到的事件各自发生时获得的信息之和,即: $h(x,y) = h(x)+h(y)$ ,由于x,y的是两个不相关的事件,那么也满足 $p(x,y)=p(x)*p(y)$
根据以上两个性质,我们容易看出h(x)一定与p(x)的对数有关(因为只有对数形式的真数相乘之后,能够对应对数的相加形式,可以试试)。因此我们有信息量公式如下:
\[h(x) = -{log_{ {2}}}p(x)\]
注;①其中,负号是为了确保信息一定是正数或者是0,总不能为负数吧!信息量取概率的负对数,其实是因为信息量的定义是概率的倒数的对数。而用概率的倒数,是为了使概率越大,信息量越小,同时因为概率的倒数大于1,其对数自然大于0了。
②为什么底数为2:这是因为,我们只需要信息量满足低概率事件x对应于高的信息量。那么对数的选择是任意的。我们只是遵循信息论的普遍传统,使用2作为对数的底!
信息熵
信息量度量的是一个具体事件发生了所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。简单的讲,信息熵就是平均而言发生一个事件我们所得到的信息量的大小
这里信息熵就表示为$H(x)=-\sum_{i=1}^{n} p(x_i)log_{ {2}}p(x_i)$,且当i=0时,定义$0log0=0$
条件熵
在决策树的分裂过程中,我们不但需要考察本节点的不确定性或纯度,而且还要考察子节点的平均不确定性或平均纯度来决定是否进行分裂。子节点的产生来源于决策树分支的条件,因此我们不但要研究随机变量的信息熵,还要研究在给定条件下随机变量的平均信息熵或条件熵
官方定义的条件熵如下:
X给定条件下,Y的条件概率分布的熵对X的数学期望(已知随机变量X条件下随机变量Y的不确定性)
\[H(Y|X)=\sum_{i=1}^{n} H(Y|X=x_i)\]
- 那么条件熵到底是个啥嘞….
这一块比较复杂。。让我想想怎么填这个坑~(再补)
暂时来讲,我的理解是按一个新的变量的每个值对原变量进行分类,比如天气冷暖和我穿衣服多少是有联系的。假设X表示我穿衣服多少(假设只有2种情况,穿多或者穿少),Y表示天气冷暖,那么H(Y|X)表示的是在确定路人穿衣情况下天气冷暖的情况的不确定性的数学期望。这个例子把天气冷暖按照穿的多少分为两类。在每一个小类里面,都计算一个小熵,然后每一个小熵乘以各个类别的概率,最后求和,就是条件熵。
信息增益
(特征选择的一个重要指标,他定义为一个特征能够为分类系统带来多少信息,带来的信息越多,说明该特征越重要,相应的信息增益也就越大)
task01练习
1.1定义X,Y的联合熵为 $H(Y,X)$ 为 ${E_{ {(Y,X)~p(x,y)}}}[−log_{ {2}}p(Y,X)]$
请证明如下关系: $G(Y,X)=H(X)−H(X|Y),G(Y,X)=H(X)+H(Y)−H(Y,X),G(Y,X)=H(Y,X)−H(X|Y)−H(Y|X)$
下图被分为了A、B和C三个区域。若AB区域代表X的不确定性,BC区域代表Y的不确定性,那么$H(X)、H(Y)、H(X|Y)、H(Y|X)、H(Y,X)和G(Y,X)$分别指代的是哪片区域?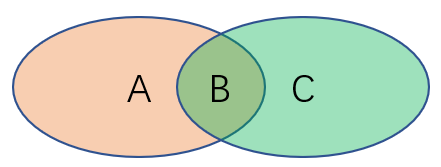
2.假设当前我们需要处理一个分类问题,请问对输入特征进行归一化会对树模型的类别输出产生影响吗?请解释原因。
不会,树模型主要依赖的是数据的信息增益基尼系数等,算是一种特征分布的顺序,归一化只改变了数值,并不改变数据的排列
3.如果将系数替换为$1−\gamma^2$ ,请问对缺失值是加强了还是削弱了惩罚?
削弱,
4.如果将树的生长策略从深度优先生长改为广度优先生长,假设其他参数保持不变的情况下,两个模型对应的结果输出可能不同吗?
不可能,深度优先和广度优先只是搜索时的顺序不同,结果相同
5.在一般的机器学习问题中,我们总是通过一组参数来定义模型的损失函数,并且在训练集上以最小化该损失函数为目标进行优化。请问对于决策树而言,模型优化的目标是什么?
信息增益最大化吧
6.对信息熵中的log函数在p=1处进行一阶泰勒展开可以近似为基尼系数,那么如果在p=1处进行二阶泰勒展开我们可以获得什么近似指标?请写出对应指标的信息增益公式。
7.除了信息熵和基尼系数之外,我们还可以使用节点的$1−max_kp(Y=y_k)$和第m个子节点的$1−max_kp(Y=y_k|X=x_m)$来作为衡量纯度的指标。请解释其合理性并给出相应的信息增益公式。
8.为什么对没有重复特征值的数据,决策树能够做到损失为0?
按道理来讲,一棵决策树应该会拟合全部的数据,所以就不存在损失
9.如何理解min_samples_leaf参数能够控制回归树输出值的平滑程度?
Task03 集成模式
$y = f(x)$
\[y = {f_{ {g_1}}}(x)\]



